About
In modern software landscapes multiple applications, which co-exists in potentially multiple versions, share one database as their single point of truth. Managing the multitude of depending schema versions manually is highly error-prone and accounts for significant costs in software projects. Developers have to realize the translation of data accesses between schema versions with hand-written views, triggers, and migration script. With InVerDa we will develop concepts and tools for integrated, easy, and robust versioning of databases. The key idea is to rethink the way of evolving to new schema versions. We use the richer semantics of a descriptive database evolution language to generate all the required artifacts automatically. The developer only needs to specify compact and easy to write descriptions of the evolution to a new schema version, which is then immediately accessible without any further manual implementation.
Online Demo: InVerDa.de
A video summarizing the challenge of database versioning and presenting a screencast of InVerDa: https://youtu.be/mzZNnpla_n4
A video showing our demonstrator: https://youtu.be/MtqD2FSTvCk
We decouple the logical external schema versions, from the actual internal physical materialization. Developers describe the evolution of external schema versions using InDEL, a language which contains invertible evolution operations [3]. Each InDEL operation contains both the changes of the schema and the currently existing data. We use the richer semantics of InDEL to automatically generate views for each schema version, as well as triggers to enable writes on any schema version. So, all schema versions stay continuously accessible, without any further line of SQL, hence InVerDa makes database versioning robust and foolproof.
Let’s consider a task management system called TasKy, which users can install on their desktops and which is backed by a central database. TasKy allows users to create new tasks, list, update, and delete them. Each task has an author and a priority ranging from 1 to 3 with 1 being most urgent. At first, we create the naive schema as shown below. As users like to have their most urgent tasks listed on their phone, we additionally incorporate a third party phone app called Do!. To match its schema, we simply execute the InDEL evolution script as shown in the figure. The TasKy data is immediately available to be read and written through the newly incorporated Do! app. At this point InVerDa has already simplified our job significantly.
For the next release TasKy2, we decide to normalize the table Task. Since we plan a stepwise roll-out of TasKy2, the old schema of TasKy has to remain alive until all clients have been updated. With the InDEL evolution script shown below, InVerDa creates the new schema version and ensures that all write operations to any of the three schema versions are propagated to all other schema versions. Assume user Ann has already upgraded to TasKy2 and changes the priority of Organize party to 1, then this task will immediately occur in the Do! app on her phone.
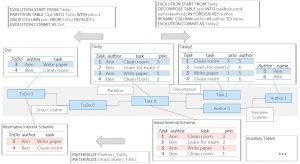
At first, the data is primarily kept in the initial schema version as shown above. However, the decoupling of the availability of external schema versions and the actual materializing schema allows to easily change this materializing schema. Assume, some weeks after releasing TasKy2 the majority of the users have upgraded to the new version. TasKy2 comes with its own phone app, so that the schema TasKy and Do! are still accessed but merely by a minority of users. Hence, it seems appropriate to migrate data physically to the TasKy2 schema, now.
Traditionally, we would have to write a migration script, which moves data, and implements new views and triggers. With InVerDa, we achieve the same blindfold with the one-liner: MATERIALIZATION TasKy2; Upon this statement, InVerDa transparently runs the physical data migration and updates the involved views and triggers of all schema versions. All schema versions stay available; read and write operations are merely propagated to a different materializing schema, now.
Internally, InVerDa represents the InDEL operations as sets of Datalog rules, which gives as several nice advantages:
- We have formally shown the correct and complete invertibility of all InDEL operations.
- We generate the delta code(views, triggers, migration scripts) directly from Datalog rules.
- We can easily add and change InDEL operations by specifying their Datalog rules.
- There are many more opportunities regarding combination and optimization of evolution operations, which we will investigate in the future.
Thanks for your interest in InVerDa. Feel free to approach us for any questions, feedback, or ideas.
This work is funded by the German Research Foundation (DFG) within the RoSI Research Training Group (1907).
Related Publications

Living in Parallel Realities – Co-Existing Schema Versions with a Bidirectional Database Evolution Language.
@inproceedings{,
author = {Kai Herrmann and Hannes Voigt and Jonas Rausch and Andreas Behrend and Wolfgang Lehner},
title = {Living in Parallel Realities – Co-Existing Schema Versions with a Bidirectional Database Evolution Language},
booktitle = {SIGMOD'17, Proceedings of the 2017 International Conference on Management of Data, Chicago, IL, USA, May 14-19, 2017},
year = {2017},
month = {5},
location = {Chicago, IL, USA},
numpages = {12},
publisher = {ACM}
}@{,
author = {Kai Herrmann and Hannes Voigt and Thorsten Seyschab and Wolfgang Lehner},
title = {InVerDa \&\#8211; The Liquid Database},
year = {2017},
month = {3},
location = {Stuttgart}
}@{,
author = {Kai Herrmann and Hannes Voigt and Jonas Rausch and Andreas Behrend and Wolfgang Lehner},
title = {Robust and simple database evolution},
journal = {Information Systems Frontiers},
year = {2017},
month = {1},
url = {http://dx.doi.org/10.1007/s10796-016-9730-2}
}@{,
author = {Kai Herrmann and Hannes Voigt and Thorsten Seyschab and Wolfgang Lehner},
title = {InVerDa \&\#8211; co-existing schema versions made foolproof},
year = {2016},
month = {5},
location = {Helsinki, Finland}
}@article{,
author = {Wolfgang Lehner and Hannes Voigt and Kai Herrmann},
title = {Logical Data Independence in the 21st Century \&\#8211; Co-Existing Schema Versions with InVerDa},
journal = {CoRR},
year = {2016},
url = {http://arxiv.org/abs/1608.05564}
}@article{,
author = {Wolfgang Lehner and Hannes Voigt and Kai Herrmann},
title = {CoDEL \&\#8211; A Relationally Complete Language for Database Evolution},
booktitle = {Advances in Databases and Information Systems - 19th East European Conference, ADBIS 2015, Poitiers, France, September 8-11, 2015, Proceedings},
series = {Lecture Notes in Computer Science},
volume = {9282},
year = {2015},
isbn = {978-3-319-23134-1},
pages = {63--76},
url = {http://dx.doi.org/10.1007/978-3-319-23135-8_5},
publisher = {Morzy, Tadeusz; Valduriez, Patrick \& Bellatreche, Ladjel}
}
Advisor for the Materialized Schema of a Versioned Database
Jonas Rausch October 1st, 2015 until March 31st, 2016
Diplom ThesisSupervision: Kai Herrmann
RoDEL - Eine Evolutionssprache für Rollenbasierte Datenbanken
Thorsten Seyschab January 1st, 2017 until March 20th, 2017
Bachelor ThesisSupervision: Kai Herrmann