About
Spreadsheets are one of the most successful content generation tools. Their ease of use and abundant functionalities equip novices and professionals alike with the means to create, transform, analyze, and visualize data. As a result, large quantities of information and knowledge are stored in this format. Clearly, this calls for automatic approaches to examine, interpret, and reuse the spreadsheet contents.
However, the high degree of freedom results in very complex sheets. Quite often, the actual data is intermingled with formatting, formulas, layout artifacts, and other implicit information. Thus, fully automatic processing for arbitrary spreadsheets has been rather difficult to implement. A human analyst still has to perform a significant part of the task manually. All in all, this results in time-consuming and cumbersome (business) processes.
In this project, we mainly address challenges with respect to spreadsheet table recognition and layout inference. We show that it is possible to perform these tasks with considerable accuracy, in a dataset of diverse spreadsheets. Our proposed approaches can be found in the Related Publications section. Moreover, we make available the material used for this work. The reader might be interested in our dataset of annotated spreadsheets, as well as on our annotation tool (refer to the downloads section).
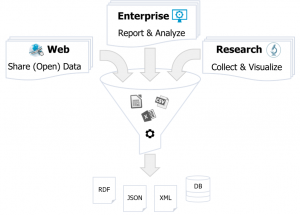
Figure 1: Extracting Information from Diverse Spreadsheets
There are many sources of spreadsheet files out there, as shown in the figure above. We aim at processing such diverse collections of spreadsheets, in a mostly automatic fashion. The inferred meta-information (e.g., layout and structure of the contents) can be attached to the original file, so to be reused for future information retrieval tasks. However, this meta-information could also serve other purposes, such as data transformation, compliance, and fault detection.
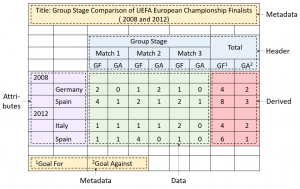
Figure 2: Cell Layout Roles as defined in the DeExcelerator Project
The first step of our proposed solution is layout inference. Contrary to related work, we focus on the cell level. The goal is to predict the layout role of each cell. For this, we trained a classifier in a supervised fashion, considering a wide range of features, many of which not covered before in the literature. We study formatting, contents, formula references, as well as the surroundings of the cell (i.e., features of neighboring cells), to predict its layout. Furthermore, our work includes novel techniques for detecting and repairing incorrectly classified cells in a post-processing step. The experimental evaluation shows that our approach delivers good accuracy, in a dataset with a considerable diversity of cells. More specifically, our dataset consists of 854 Excel sheets, randomly selected from three distinct corpora with different characteristics: FUSE, ENRON, and EUSES.
Secondly, we focus on the table recognition task. We adhere to identify and extract data from tables since they are a great source of structured and factual information. In comparison to related work, we avoid assumptions with respect to the number of tables and their arrangement in the sheet. Additionally, we enforce a certain level of flexibility, which allows us to work even with problematic tables (e.g., containing misclassifications and/or empty cells). Thus, we do not limit our approach to a set of predefined expected formats. This goes hand to hand with our decision to work on the cell level, as our overall goal is to handle spreadsheets differing in layouts and contents.
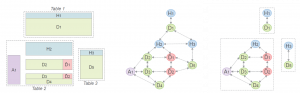
Figure 3: Table Identification via a Graph Representation
This project among others has produced several publications on spreadsheet table recognition. The figure above is taken from one of our latest papers, where we use a graph representation to identify candidate tables. After classification, we group together cells of the same layout role to form coherent regions. These regions correspond to the nodes of the graph. While the edges capture the spatial arrangement of the regions in relation to each other. For more details, please check the related publications.
In addition, this work has produced an annotation tool, which we have used to generate training and testing datasets. The video below demonstrates the tool
Downloads
Use the following links to access the components used for this research project.
- Source Code for Spreadsheet Annotation Tool (Git Hub) *
- Executable Jar for Annotation Tool *
- DECO Dataset (Published ICDAR ’19)
- Annotations Exporter
* The Spreadsheet Annotator tool it is still in development phase. It has been tested so far in Windows 7 SP1 with Microsoft Office Excel 2013.
Related Publications
@article{,
author = {Oscar Romero and Elvis Koci and Wolfgang Lehner and Maik Thiele and Julius Gonsior},
title = {XLIndy: Interactive Recognition and Information Extraction in Spreadsheets},
booktitle = {The 19th ACM Symposium on Document Engineering (DocEng)},
year = {2019},
month = {09},
numpages = {4},
url = {https://doceng.org/doceng2019}
}@article{,
author = {Oscar Romero and Elvis Koci and Wolfgang Lehner and Maik Thiele},
title = {A Genetic-based Search for Adaptive Table Recognition in Spreadsheets},
booktitle = {International Conference on Document Analysis and Recognition (ICDAR)},
year = {2019},
month = {09},
numpages = {6},
url = {https://icdar2019.org/},
crossref = {DBLP:conf/icdar/}
}@article{,
author = {Oscar Romero and Elvis Koci and Wolfgang Lehner and Maik Thiele},
title = {DECO: A Dataset of Annotated Spreadsheets for Layout and Table Recognition},
booktitle = {International Conference on Document Analysis and Recognition (ICDAR)},
year = {2019},
month = {09},
location = {Sydney, Australia},
numpages = {6},
url = {https://icdar2019.org/},
keywords = {Spreadsheet, Dataset, Enron, Corpus, Annotation, Recognition, Layout, Table, Templates},
crossref = {DBLP:conf/icdar/}
}@article{,
author = {Elvis Koci and Maik Thiele and Oscar Romero and Wolfgang Lehner},
title = {Table Recognition in Spreadsheets via a Graph Representation},
booktitle = {13th IAPR International Workshop on Document Analysis Systems (DAS)},
year = {2018},
month = {4},
isbn = {978-1-5386-3346-5},
pages = {139--144},
url = {http://doi.ieeecomputersociety.org/10.1109/DAS.2018.48},
publisher = {IEEE Computer Society},
keywords = {Spreadsheet, Table Recognition, Graph Representation, Document Analysis},
crossref = {DBLP:conf/das/2018}
}@inbook{,
author = {Elvis Koci and Maik Thiele and Oscar Romero and Wolfgang Lehner},
title = {Cell Classification for Layout Recognition in Spreadsheets},
booktitle = {Knowledge Discovery, Knowledge Engineering and Knowledge Management, IC3K 2016, Revised Selected Papers},
series = {Communications in Computer and Information Science},
year = {2018},
publisher = {Springer},
keywords = {Speadsheet, Tabular, Table, Document, Layout, Recognition, Analysis, Classi cation}
}@article{,
author = {Elvis Koci and Maik Thiele and Oscar Romero and Wolfgang Lehner},
title = {Table Identification and Reconstruction in Spreadsheets},
booktitle = {29th International Conference on Advanced Information Systems Engineering},
year = {2017},
month = {6},
isbn = {978-3-319-59536-8},
location = {Essen, Germany},
pages = {527--541},
numpages = {15},
url = {https://doi.org/10.1007/978-3-319-59536-8_33},
publisher = {Springer}
}@conference{,
author = {Elvis Koci and Maik Thiele and Wolfgang Lehner},
title = {A Machine Learning Approach for Layout Inference in Spreadsheets},
booktitle = {8th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management},
volume = {1},
year = {2016},
month = {11},
isbn = {978-989-758-203-5},
location = {Porto, Portugal},
pages = {77--88},
numpages = {12},
url = {http://dx.doi.org/10.5220/0006052200770088},
publisher = {SCITEPRESS }
}
DeExcelerator: a framework for extracting relational data from partially structured documents.
@article{,
author = {Julian Eberius and Christoper Werner and Maik Thiele and Katrin Braunschweig and Lars Dannecker and Wolfgang Lehner},
title = {DeExcelerator: a framework for extracting relational data from partially structured documents},
booktitle = {22nd ACM International Conference on Information and Knowledge Management, CIKM'13, San Francisco, CA, USA, October 27 - November 1, 2013},
year = {2013},
isbn = {978-1-4503-2263-8},
pages = {2477--2480},
numpages = {4},
url = {http://doi.acm.org/10.1145/2505515.2508210},
publisher = {He, Qi; Iyengar, Arun; Nejdl, Wolfgang; Pei, Jian \& Rastogi, Rajeev}
}
Min-Cut Graph Partitioning for Table Identification in Spreadsheets
Michael Günther June 1st, 2017 until September 12th, 2017
Project Thesis
Context-based Layout Inference in Spreadsheets Using LSTM
Dominik Rivoir September 15th, 2017 until April 23rd, 2018
Project Thesis
Active Learning for Spreadsheet Cell Classification
Josephine Rehak October 16th, 2017 until April 16th, 2018
Project Thesis
Clustering Cells in Spreadsheets based on Style and Content Similarities
Anna Elke Brauer October 16th, 2017 until February 5th, 2018
Project Thesis

Related Student Theses
Analysis and reasoning on spreadsheat references
Michael Hoppe January 1st, 2017 until January 1st, 2017
Diplom Thesis
Investigating Graph Partitioning Strategies for Table Identification in Spreadsheets
Jasmin Mohnke January 15th, 2018 until April 2nd, 2018
Bachelor Thesis
Development of an Excel-frontend for Table Identification in Spreadsheets
Thomas Grosche November 20th, 2017 until March 6th, 2018
Bachelor Thesis
Developing an Excel-Frontend for Extracting Relational Data from Spreadsheet
Ljupka Titizova June 19th, 2017 until September 4th, 2017
Bachelor Thesis
Optimal Cell Classification in Spreadsheets
Alexander Volkmann May 23rd, 2017 until August 8th, 2017
Bachelor Thesis
Extending Sequential Covering to Fix Misclassifications
Markus Bürger November 1st, 2016 until March 8th, 2017
Bachelor Thesis