| Time: | upon consultation |
| Quantity: | 0V/0Ü/8P |
| Language: | German (English on request) |
| Modules: | INF-04-KP, INF-PM-FPG, MINF-04-KP-FG3 |
FPSyA 1: Lightweight Data Compression in MorphStore
This internship is addressed to students, who have successfully worked with MorphStore in a previous course and want to extend their abilities in database systems programming.
For analytical workloads, in-memory column-store database systems are perfectly suited, because relational tables are organized by column rather than by row. The major advantage of these systems is that analytical queries only need to read relevant data columns during query processing. However, the transfer of these columns between main memory and CPU has become a bottleneck in query processing, because of the limited memory bandwidth. A way to overcome this issue, is to use the available bandwidth efficiently by compressing the base data as well as the indermediates. This way, less data has to be transferred. In concurrency to the saved bandwidth, there is the cost of compression and decompression. For this reason, recent systems encode their columns as integers and apply lightweight integer compression as opposed to heavy-weight compression. Lightweight compression implements less complex algorithms than heavyweight compression. MorphStore uses this approach, but only a limited number of compression techniques is currently available. This goal of this course is to introduce an additional compression technique into morphstore, including not only compression, but also specialized operators working directly on the compressed data.
For further information and registration, please contact Annett Ungethüm or Patrick Damme.
Slides
15 Apr: Kick-Off
22 Apr: Compression
29 Apr: Efficient Compression
06 May: Towards Specialized Operators
13 May: Specialized Operators
FPSyA 2: Extension of the Template Vector Library for ARM
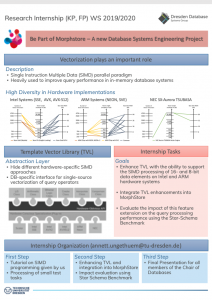
Background
For analytical workloads, in-memory column-store database systems are perfectly suited, because relational tables are organized by column rather than by row. The major advantage of these systems is that analytical queries only need to read relevant data columns during query processing. To further speedup query processing, vectorization based on the SIMD (Single Instruction Multiple Data) parallel paradigm is a core technique. In mainstream CPUs, vectorization is offered by a large number of powerful SIMD extensions growing not only in vector size but also in terms of complexity of the provided instruction sets. However, programming with vector extensions in a non-trivial task and accomplished in a hardware-conscious way. Thus, the implementation of query operators is not only error-prone but also connected with quite some effort for embracing new vector extensions or porting to other vector extensions. To overcome that, we developed a Template Vector Library as a hardware-oblivious concept. The unique properties of TVL are: (i) we provide a well-defined, standardized, and abstract interface for a vectorized query processing, (ii) query operators have to be vectorized only once using TVL, and (iii) this single set of query operators can be mapped to all vector processing units from different SIMD extensions up to vector engines at runtime. Moreover, our TVL approach is a core component of MorphStore, a regular in-memory column-store database systems with some unique feature designed and implemented at our chair.
Research Internship Organization
In this research internship, we will have a deep dive into SIMD programming and TVL, in particular, we are going to enhance TVL with some new features. To achieve that goal, the internship is organized as follows:
- At the beginning, we will give a tutorial-style introduction into SIMD programming so that the subsequent tasks can be mastered. That means, we do not expect that our participants have extensive experience with the SIMD implementation but with C++ programming in general.
- Afterwards, we will introduce all concepts and implementation aspects of our hardware-oblivious TVL approach.
- Generally, SIMD processing can be done on 64-, 32-, 16-, and 8-bit data elements. Up-to-now, our TVL only supports all of these element sizes on Intel, but not on ARM cores, which only supports 64 bit. Thus, the main task of the research internship participants is to enhance TVL with the ability to support also the SIMD processing of 32-, 16-, and 8-bit data elements on ARM cores.
- At the end, we will integrate these extensions into MorphStore and we will evaluate the impact of this feature extension on the query processing performance.
Please be aware that some experience in C++ programming is required to successfully finish this course!*
*Successfully finishing the practical Computergraphik exercises is a good indicator that you are properly prepared.
For further information and registration, please contact Annett Ungethüm or Dirk Habich.